Two weeks ago, I went to the FOSS Backstage conference in Berlin. I have been to one before, and also presented virtually on it, but this was the first time with a full size talk on-site. Even though it was the first time I talked on this topic, it felt okay. And now the video of the talk Using the commons without causing a tragedy is published on their YouTube channel.
All in all, the conference was well organized and the catering was lovely. I am looking forward to participate in and contribute to future editions of FOSS Backstage.
On Tuesday, 29 October, Wikidata turns twelve, and I had been thinking about creating a small birthday gift to celebrate. Earlier, I had experimented with creating an animated background to use in our Editing Wikidata live streams, but never got one that worked well. But the thought popped up again, and perhaps I could do something different.
As it were, another thought I had also been pondering was how to do a refresh on the older web slides I used to present and if I could use the animated background I have on aina.li. Two thoughts turned into one, and I made an animated Wikidata background for the web.
Yes, it is a bit silly, and not hugely useful for the sum of human knowledge, but a celebration has to be a bit fun too. So happy 12th birthday Wikidata, I hope you enjoy all your gifts.
We are in the midst of a hype around Artificial Intelligence (AI) and the market is trying to get ahead of each other in all sorts of ways. One way is to claim that their AI is open source. So far, there has been a lot of open washing, meaning that they claim they are open but failing to apply common practices, like licenses approved by the Open Source Institute (OSI) to make that clear. This is so common, some weekly newsletters even have recurring segments listing all perpetrators.
Adding to this, there is an ongoing discussion about what open source for AI should mean, and OSI is even drafting a new definition for this. As late as today at the OSPOs for good conference, some big companies tried to claim that there is a gradient of open source, and if not, threatened not to be supportive of open source at all, and that seems just disingenuous to me. Through various venues, webinars and chats, I have tried to make a point of something that seems obvious to me, which leans back on the original four software freedoms. So before going further, let’s just remind ourselves of these.
The four freedoms of free software
The freedom to run the program as you wish, for any purpose (freedom 0).
The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.
The freedom to redistribute copies so you can help your neighbor (freedom 2).
The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
These freedoms are not a gradient, all four are needed, or it is not free and open source software.
It might be worth mentioning that OSI’s definition of open source is quite aligned with the spirit of these, and in some of their points even clearer. For example, their second point about source code includes the following clarification:
The source code must be the preferred form in which a programmer would modify the program. Deliberately obfuscated source code is not allowed. Intermediate forms such as the output of a preprocessor or translator are not allowed.
These two definitions have led me to the following arguments.
My arguments about the freedoms
In various venues, I have had arguments essentially like the one below.
Me: So to be able to study the AI and to modify it in any way, I need access to the data that the models have been trained on. If I can’t see, remove, add, or modify the data, I don’t have full freedom to study the AI or change it to suit me. Essentially, it is a black box, and it doesn’t matter if the weights are free because I can’t change what is weighted.
Them: But we cannot open source the data because we don’t own the copyright of the data we trained the models on.
Me: …
So they openly admit that the system as a whole is not free.
In my opinion, such AI systems per definition are not, and cannot be, viewed to be free open source software.
Another similar discussion starts with me doing the same rant, but is followed in a slightly different way.
Them: But we cannot publish the data because even though we made sure we own the copyright of the data, it includes private data and personal information.
Me. …
Now, I have to give it to them that we are a bit closer. But I still don’t have freedom 1, I can for example not clean the data from biased or erroneous private data to make the model better. There is also a risk that distributing the model would distribute access to these private data if I change other parts of the system, and thus the risk of me breaking laws doesn’t really give me freedom 3.
Where will we end up?
In conclusion, the essence of truly open source AI lies not only in the accessibility of the code or the weights but also in the freedom to access, modify, and distribute the data upon which these models are built. Without freely licensed and fully accessible training data, the promises of transparency, collaboration, and improvement inherent in the open source ethos remain unfulfilled. The four freedoms that define open source software are undermined when data remains proprietary or restricted. As the discourse around open source AI continues to evolve, it is imperative that we push for these clear values of freedom and openness, or we risk heading into a future we rely on black boxes, blind trust and reduced possibilities to shape the software as we wish.
In addition, we should perhaps find a term that can be used for other types of AI systems. Reusable, gratis, or shareware might be terms to use for that. If you have ideas, please let me know.
I was watching Open Source Fridays streamed on Github’s YouTube channel a little more than a week ago and was struck by how they went about recommending people find projects to contribute too. They were discussing metrics about projects, so I left a comment in the chat.
I would not recommend that way of selecting a project to contribute to. Much better is to contribute to something that you use and where you like to see an improvement.
Even though my pushback was well-received, I feel my point was missed. The host only went so far as to defining “use” as cloning it and getting it running.
Is there a right way to contribute to Open Source?
Yesterday, Edoardo Dusi published a needed blog post on opensource.net with thoughts aligned with mine. He titled it There is a right way to contribute to Open Source and delves deep into the hype surrounding stars and likes. He also provides a great list of other ways of contributing that are not reflected in the most common metrics. Go read it; it is well-written and what sparked this blog post.
Where to contribute
While Dusi touches upon contributing to projects he is familiar with, I want to emphasize the point more clearly. Perhaps it felt so obvious to him, he didn’t feel the need to state it. But as a Wikipedian, I am used to stating the obvious so let me delve a bit deeper into it.
The point that I tried to make in the livestream, and what came so naturally to Dusi, is that it is much easier to contribute to an open source project if you are familiar with it because whatever they build is part of your workflow and that the workflow depends on it working. Knowing what the software is trying to do and the aims of at least one end user (that being you) can really help you along the way when making contributions.
But we are not there yet. Because if you are anything like me, and mostly rely on open source tools, it may not narrow it down much. In that case, I think there are basically three strategies to pick from: your need, your joy, and their need. These were ordered, and I’ll delve into each of them and explain why I think this is the order to consider. I will also mention some, in my important, properties of codebases related to this.
Your need for a change in the codebase
I believe this is partly what Dusi was talking about when he mentioned business motivation. But whereas he described a larger tit-for-tat scenario that would lead to long-time gains in the codebase, I really mean something more direct, as referred to in “scratch your own itch”. By solving a problem in a workflow or tool that you are experiencing yourself, not only do you have in-depth knowledge of the problem, you are also properly motivated to solve it. The reward becomes inherently tangible because you will reap it yourself. And while sometimes it may not actually be worth the time, the joy of seeing your improvement every time you are in that workflow may be very satisfying.
Example – Wikidata SPARQL service
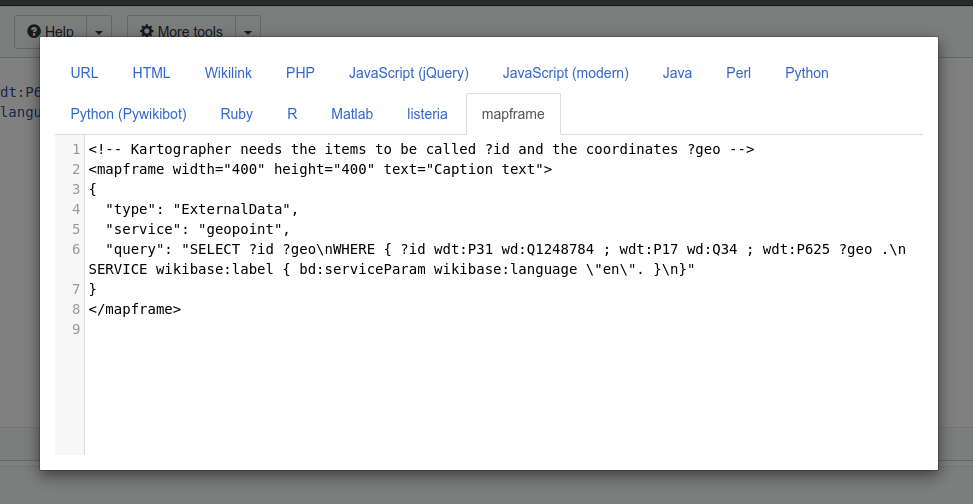
I often use the Wikidata SPARQL service to create map queries that I later used on Wikipedia. But to add them to an article, there was always a step in reformatting the query as Mediawiki did not accept the line breaks similarly to the query service. Therefore, in a hackathon, I wrote a tiny conversion tool and got it added to the code snippets export functionality so that I now just need to copy and paste every time I do a new query.
The mapframe code snippet.
Your joy of making a contribution
This motivation may be a variation of the former, but I distinguish it separately because often there might not be a direct reward in some of your workflows. What I group in this category are projects that you are charmed by and just want to exist in the world. It could because they are just fun ideas that tickle your mind, or a civictech project that you feel is important to the world somehow. In this group, I would also place most of the motivations that Dusi mentioned, the long-term view of improving some part knowing that others will improve other parts down the line, making the entire project better.
Example – Weeklypedia
Weeklypedia is an automated weekly statistics generator, showing which articles on a language version of Wikipedia got the most edits last week. I don’t really use this knowledge for anything, but I think it is a fun tool, and it gives me a peek into what is on my fellow editors’ minds this week. Here, I could translate the interface to Swedish, and now I get the newsletter delivered to my inbox in my native language. Easier to read for me, and it feels great that it might also lower the barriers for others.
Their need of help
Perhaps surprisingly, the next option in my recommended order is to look at young or small communities rather than the big and “healthy” ones from within the software you are using. My reasons are two-fold.
First, in a small community, even a tiny contribution can have a lot of impact. Not only because you might actually be accelerating the development by a considerable amount, but also because in a smaller community, someone else caring might raise the spirits in the community by orders of magnitude.
Secondly, if your plan was to start an “open source career”, in a small community it may be a shorter step to be delegated more responsibilities and have an impact on the direction of development. Now, keep in mind that not all small communities are looking for contributions and collaboration; it might be a single person’s pet project, so check that your help is wanted before you get started.
Example – OpenRefine
I have been an OpenRefine user for many years, and even did a few video tutorials showing my workflows with the tool. Two years ago, the advisory committee needed a new member, and since one of the staff knew that I was showcasing the tool, I was asked if I would consider helping. Now, OpenRefine is neither small nor new, but there was clearly a need from their side. Since I had experience from being on NGO boards from before, it felt like an excellent way for me to help the community, even though technical contributions here is beyond my skills.
Other properties to consider
Even within these groups, you might have several codebases that you are considering contributing to, and then I think there are some properties that make sense to review.
Ease of collaboration
It might not be surprising that I think that ease of collaboration is an important property of a codebase; after all, for the last five years I was working on the Standard for Public Code, which is all about making it easier to contribute a codebase. Besides the obvious benefit of making it easier for yourself when contributing, it is also a strong signal of a community who wants more people to join them. So if a codebase has a well crafted contributing file or other ways that guide a new contributor into the community and make them (and you!) feel welcome, I would suggest it is a codebase well worth investing your time in.
External rewards
Only lastly, I want to acknowledge the external rewards. Especially if you are looking for a professional career, there are signals that a future employer might be looking for. Now, I want to emphasize that I believe that these in themselves are poor criteria to start with when you are looking for a project to help. But if you are looking at two projects that are equal in all other aspects, it would be naive to suggest that these “fame metrics” would not matter, whether we like it or not.
To be fair, I admit having participated in Hacktober fest and got the t-shirt, and to have submitted codebases I am working in to it and other campaigns. But today, I see these phenomena more as a way to explore new tools and to do outreach, rather than a path for impactful contributions and fame.
Conclusion
In conclusion, contributing to open source is not merely about following metrics or seeking external validation. It’s about finding alignment between your own needs, passions, and the needs of the projects you engage with. As Edoardo Dusi suggested, there is indeed a right way to contribute to open source—one that transcends the superficial measures of popularity and, in my opinion, starts from within you and your needs.
Whether you’re addressing your own pain points, finding joy in nurturing projects close to your heart, or answering the call for help in communities in need, the essence of open source contribution lies in the depth of your engagement and the authenticity of your motivations.
In 2022, I wrote a blog post about my podcast listening. Since I recently switched podcast player, and with that did a big cleanse, I thought it was time for an update.
I used to use the Podcast addict app for listening to podcasts. And it was actually quite good and had all the features I wanted. But it was one thing itching, it wasn’t open source. So last year I finally did some research and installed AntennaPod, an open source solution that I saw was getting good reviews.
The migration was as easy as one could hope for, and one neat feature was that it asked which of my subscriptions I wanted to keep. This made me contemplate the ones I were enjoying, and now I have updated my listening page (archiving my previous feed). Most of the changes, though, are for podcasts that stopped producing new episodes and where I gave up hope of them returning.
One small thing that I have not figured out yet, is how to add episodes without subscribing to the podcast. But I guess I will figure that out, or make a feature request. Their contributing page looks inviting, and I have requested access to help translate the app.
On the positive note, I am already glad to not be bothered by the animated ads that pestered me in the Podcast addict app.
I somras var jag på GOTO10 i Stockholm med NOSAD och visade upp och pratade om spelet Governance game som jag ligger bakom och som jag skrev om här för ett tag sedan. Nu har vi äntligen fått upp videon från föreläsningen. I den så både förklarar vi idén med spelet, men visar också rent praktiskt hur en spelomgång går till. Om du har funderat på hur ni ska få till förvaltningen av ett mjukvarusamarbete så kan detta kanske vara inspirationen du behöver.
Earlier this week, the winners of the Sustainable Development Goals Digital Game Changer Awards were revealed. Govdirectory didn’t win, but we are still honored to have been selected as a finalist in the category Peace – Building peaceful and inclusive societies.
It would have been nice to have listed this on the slide for awards in our recent talk at Code for All, but that one was pre-recorded earlier in the summer when we didn’t know the upcoming good news.
It is now over two years ago Albin Larsson and I started the Govdirectory. Not soon thereafter, we got the honor to present it in a Code for all lightning talk. Today, we were honored again and got to do a follow-up lightning talk.
The growth of Govdirectory: 2 years and 10,000 contact points later
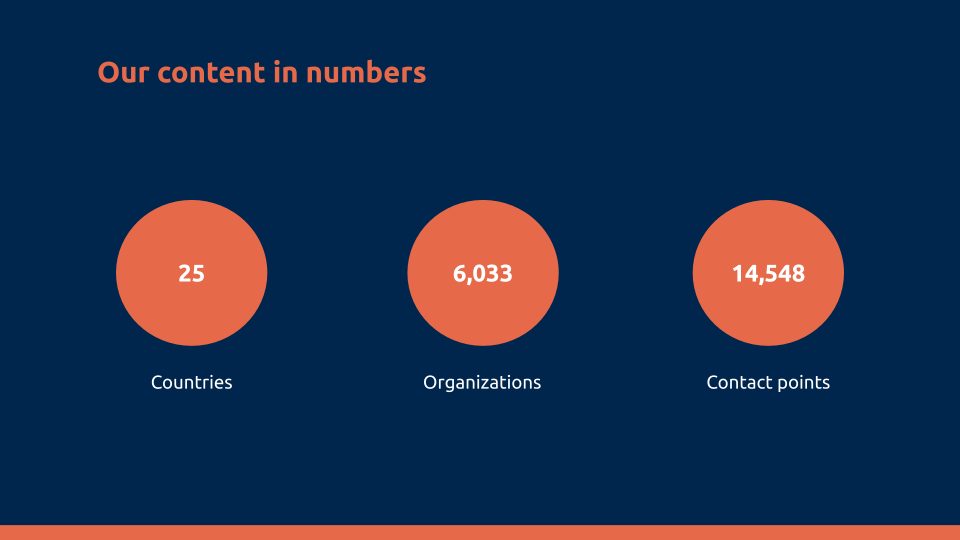
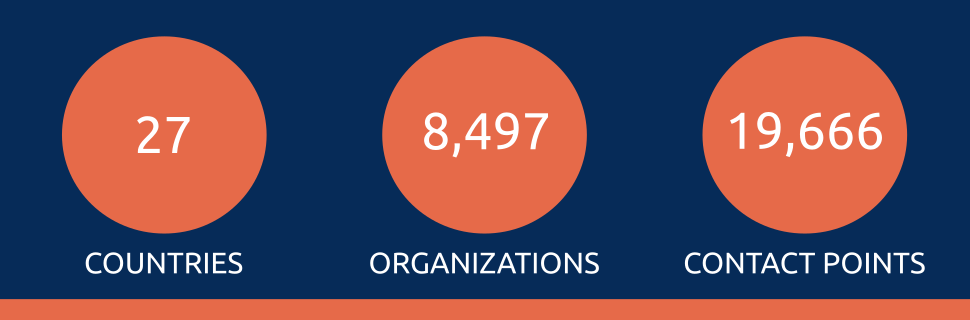
In this talk (slides), we mention some statistics.
One aspect that I love about this project is that it is not static, but is building all the time. So since we recorded the video, we have already grown substantially.
As you can see, the coverage is just over 10% of the countries in the world, and of the countries we have, only one is complete and a handful more have great coverage. If you want to help with the data, head over to the project page on Wikidata. If you have want to help improve the website, head over to the repository on GitHub. And, of course, you are also welcome to just explore what is on the website at govdirectory.org.
I was recently a guest on the podcast Between the brackets. The podcast usually covers MediaWiki related topics, but from time to time, also have Wikimedians as guests. It was a lot of fun, since we talked about almost all the things I am currently involved in. We mostly talked about the Foundation for Public Code, Wikidata, Govdirectory, Wikimedians for Sustainable Development but also a bit about AI and Abstract Wikipedia.