Earlier this year, I attended the NASA course “Open Science 101“. It was supposed to be given last year but was postponed due to technical reasons. At least it was given this year, but after completing the good course, there was some other technical (or perhaps US administrative?) challenges and it took some time before the badge could be issued. Finally it came through, and here it is, via Credly:
Okjökull blir en före detta glaciär. Jordbruk lider av oförutsägbart väder. Värmeböljor sätter människor i misär, gamla och fattiga speciellt i städer. Krisen har fatal humanitär karaktär, oroligheter lämnar barn utan fäder. Överallt skogsbränder som hotar liv och lem. Havsnivåhöjningarna dränker många hem.
Trots att det verkar otroligt komplicerat, i grunden problemen har en gemensam sak. Det är helt fel mål som vi har maximerat, om och om slagit koldioxidsrekord med brak. Allt för sällan har vi problematiserat, slarvigt trott att förändring sker i sakta mak. Låsta i systemets kortsiktiga brister. Utan omställning räcker ej aktivister.
Och fast det brådskar sparkar massorna bakut. Det är för svårt att förstå sitt eget bästa. Men det finns ingen tid för framskjutna beslut. För god effekt betyder tiden det mesta. Det är därför politiken är helt akut om vi vill förbättra för de allra flesta. Men det gäller att vi kan se bortom jaget: mot mänskligheten, det stora hela taget.
Det hänger inte på individen i sig. En enskild individ påverkar ingenting. Men ändå hänger allt och allas hopp på dig, för när någon gör något händer någonting. Att börja ställa om är upp till dig och mig. Om alla agerar kan vi ändra allting. Vi har råkat hamnat här mest utan avsikt, lösningen uppnås genom klarhet och insikt.
Almost every week, I have been updating how it is going with the goals continuously on GitHub. This review is meant to give more room for reflections on the themes I chose for 2025. For ease of reference, I have added this quarter’s goal for each theme.
Sustainability
Wikimedians for Sustainable Development 🟡
Goal: Create a great yearly report. Draft decision-making process.
The yearly report came together quite nicely, the format from previous years was still helpful, even though that the submission process now already asked questions based on the Affiliate Health Criteria. While that was a bit of a surprise when starting the submission process, thanks to those criteria being in our goals for 2025, we already had a decent baseline to use for the new report style.
When it comes to drafting a new decision-making process, I didn’t get as far as I hoped. I did a review of what other affiliates are using, and found a few models that I think could be useful for our group, but lacking feedback from other members, I didn’t make a proper draft, but I do have good hopes for the next quarter goals still.
Office of Carbon Omission 🟢
Goal: Generalize the landing page and move the form to a “library” of actions.
Early, I started to list a few ideas of a library for more ideas. But then I got stuck on figuring out the overall design. I realized, already with the tiny prototype, that adding content would increase the cost of maintaining this site that didn’t use any tooling to build it. After some research, I decided to try out 11ty to be able to generate the site at least partly automated when adding new content. I did a quick sketch in Excalidraw to help me visualize what parts needed to be reused.
Visualizing it like this helped me a lot to get things organized. While there are more to polish on, and a lot more content to add, I feel that I succeeded in my goal to create the framework to build upon at the updated site.
Openness advocacy
Open By Default 🔴
Goal: Set up a VPS for using open source tools.
I did some research and found a few providers that could give me a server with Cloudron which in turn enables many open source tools. But Cloudron itself is not open source so I would prefer something similar to Yunohost. Unfortunately, I haven’t found a provider that seems to come with that in an easy ready-to-run package. I’ll do some more research, but if I don’t find a good alternative soon, I will go with Cloudron.
While not part of the goal, I did give a presentation at FOSS Backstage, Using the Commons without causing a tragedy, which I think is worth mentioning here as it was both on the theme and gave some visibility for me and the company.
Govdirectory 🟡
Goal: Publish previously submitted fund applications and add a way to ask for funding for them.
The previous fund applications have been published as sub-pages on Wikidata, so they are fairly easy to reuse now. One plan was to adapt them for the floss.fund but the format it had was not well suited as there we have no formal organization and the community is so open and inclusive. So we still haven’t figured out a really explicit nor easy way to ask for funding.
Wikipediapodden 🟢
Goal: 12 episodes published.
This ticked on like a clock in terms of episode production and exactly 12 episodes were published.
Last year I found a platform for streaming to Fediverse, but unfortunately over the holidays, that instance went offline. Recently I found another suitable instance, and we have streamed one episode over there.
I also started on next quarter’s goal, trying out an automated editing tool (Descript), but so far nothing worth continuing with as it couldn’t handle our Swedish at all.
Book project 🟡
Goal: Research.
This was too vague of a goal. Still, while the research has been successful in the sense that I have located and acquired a lot of material to read, the sheer amount left me unfinished. But at least of what I did read, I feel I am on the right track.
Learning
German 🔴
Goal: Find a good app alternative to Duolingo.
Unfortunately, I am still stuck in Duolingo. I tried another app, DW Learn German, but it was a bit buggy so I got frustrated with it. If you have any tips, I am all ears.
Climate change 🟢
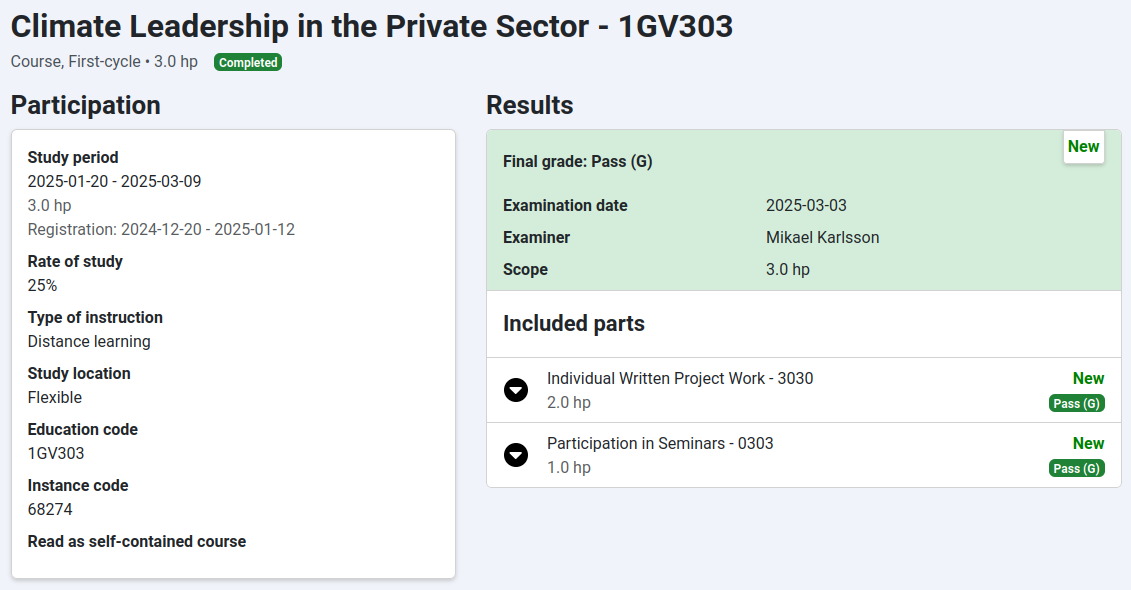
Goal: Pass the course Climate Leadership in the Private Sector.
No goals for the quarter, and of top of that I feel like I have stayed reasonably up-to-date with news. I did apply to an introductory course for the summer at Linköping University and one for the fall at Halmstad University, focused on ethics.
Health
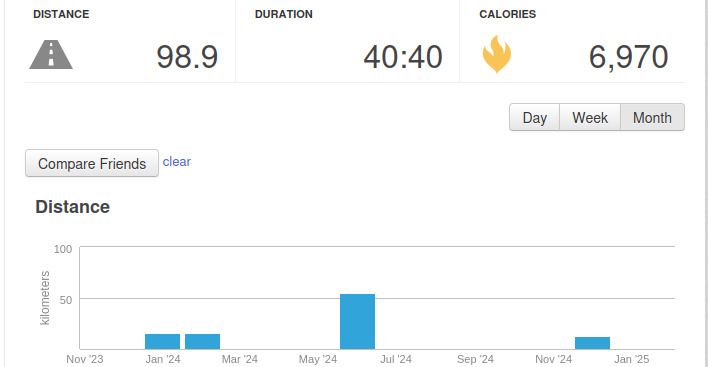
Running and hiking 🟢
Goal: 225 km (averaging 5 km/day)
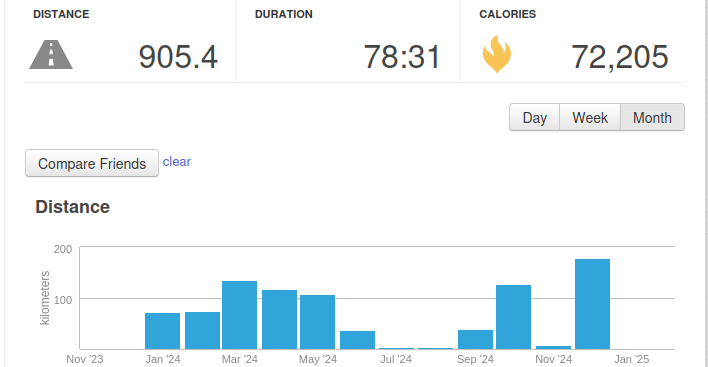
Here I am crushing it (January: 129 km, February: 100 km, March: 106 km). I have got myself a good habit of running almost every day. In January, I had a small pain in my calf, similar to my injury last year, so I did make the distances a little bit shorter each day, but the consistency still makes the average be higher than the target.
Eating 🟢
Goal: Average 19 in the Daily Dozen app
At home, checking the boxes is easy and have become a habit (January: 20.55, February: 20.64, March: 20.74). On my trip to FOSDEM in Brussels, I managed to plan meals pretty well to not loose out too much, but the FOSS Backstage in Berlin was harder. Even though the food was of unusually high quality, it was not checking the nutritional boxes to a desired extent.
Two weeks ago, I went to the FOSS Backstage conference in Berlin. I have been to one before, and also presented virtually on it, but this was the first time with a full size talk on-site. Even though it was the first time I talked on this topic, it felt okay. And now the video of the talk Using the commons without causing a tragedy is published on their YouTube channel.
All in all, the conference was well organized and the catering was lovely. I am looking forward to participate in and contribute to future editions of FOSS Backstage.
Screenshot from the central course register Ladok (the only possible grades were pass or fail).
And this time in the assignment I managed to tie together my thoughts about openness and sustainability. I wrote about how Houdini Sportswear with all their experience in sustainability can become more than a role model and even reach the level of a public educator. In this spirit, I have also decided to publish my assignment publicly and get a DOI for it (as the university does not do this by default or offer that services optionally yet). It is available on Zenodo as DOI: 10.5281/zenodo.15011039 (it is written in Swedish).
I 2019 tog jag och Magnus över programledarrollen för Wikipediapodden, och vi har hållit i sedan dess. Precis nyligen gjorde vi avsnitt 300!
Det har varit en kul resa och över tiden har vi gjort små förändringar här och där. Vi har prövat olika segment, olika längder och frekvens. Men två saker har varit konstanta.
För det första att det främst är en nyhetsuppdatering. Det var så det började, och det är också det som jag tycker främst saknas. Det gör det dessutom att vi behöver vara mindre kreativa varje vecka, eftersom att vi återspeglar vad som händer i de olika gemenskaperna.
För det andra att vi har fokuserat på att ha kul själva och vara generösa mot oss själva. Vi siktar på ett avsnitt inspelat samma tid varje vecka men om livet slänger in oväntade händelser har vi alltid enkelt spelat in en annan dag eller hoppat över en vecka. Jag tror att det är en viktig del att vi fortfarande håller på.
Samtidigt vill jag ge ett stort tack till Wikimedia Sverige som ger oss stöd för webbhotell, inspelningsprogram och teknik. Utan det skulle nog vi aldrig tagit oss dit vi är idag.
With some irregularities, I have had some New Year’s resolutions. Since 2021, these have been inspired by Daniel Mietchen, not only publishing them publicly, but also doing continuous follow-up. This year, I had the basics done on the Eve, but at the last minute, decided to go into more details, with quarterly goals, and that took some more time. But now I am done, and have even done my weekly documentation twice. Perhaps it is not really resolutions in the traditional sense, but more of themes and projects fitting in them.
My themes for the year will be Sustainability, Openness Advocacy, Learning and Health. Each of them has several and more specific sub-themes, and each of those are broken down with quarterly goals. Find the full breakdown and dashboard on GitHub.
The documentation will be different from last year. Instead of monthly updates here, I will try to update the dashboard weekly (and as much as I can, with details in the code commits) and for each quarter write one summary blog post here with reflections and possibly even course corrections.
2024 is over and just like last year, it is time to reflect on the resolutions that I made. I must admit I totally forgot to use the resolutions page as a dashboard like I was planning. But I did do quite well with monthly reports (August and September were lumped together, but otherwise great). So with those meta questions covered, how did I do on my themes?
🔴 Sustainability
make efforts so that the Wikimedians for Sustainable Development becomes a vibrant, healthy and self-sustaining user group
I want to give myself a pass on the efforts made. However, it is clearly not a vibrant, healthy and self-sustaining user group yet. Some more activity has been seen, and a few more people have shown interest in the user group, but I think it is fair to say that it isn’t vibrant. Related to the health, the Wikimedia Affiliates Committee announced that they are considering some “health criteria” which we have started talking about in the group and included in the annual plan for 2025. More on that in my 2025 blog post.
promote the Fediverse by being an active and curious community member and role model
Even though my activity some months was low, I am giving myself a weak pass, as I think I have been quite vigilante in promoting the Fediverse in various ways. This includes exploring different parts of it and not only quitting X, but also being vocal about it. Now, I am pretty sure I haven’t moved the needle on any topline numbers, but at least I am fairly certain that people who followed me in other places and peeked into the Fediverse have been finding a lively and positive part of the internet.
This year was tough. I was sick a bit and had trouble with my calves. But thanks to a good start, and new shoes enabling a strong finish, I made my goal. The running in itself was just a few kilometers from reaching the average, and with the added hiking (where I only count a third of the distance) I was averaging 5.14 km every second day (or 5 km every 1.94 day).